Multi-threaded programming is a key technology in modern software development. In multi-threaded programming, developers can decompose complex tasks into multiple independent threads and execute them in parallel, thereby taking full advantage of multi-core processors. However, multithreaded programming also brings challenges, such as thread synchronization, deadlocks, and race conditions. This article will delve into the basic concepts of multi-threaded programming ( atomic operations, CAS, Lock-free, memory barriers, pseudo-sharing, out-of-order execution, etc. ), common patterns and best practices. Through specific code examples, I hope to help everyone master the core technology of multi-threaded programming, and apply this knowledge in actual development to improve the performance and stability of the software.
Table of Contents
1 multithreading
1.1 The concept of threads
More than a decade ago, mainstream opinion advocated favoring multi-processing over multi-threading where possible. Today, multi-threaded programming has become the de facto standard in programming. Multi-threading technology has greatly improved the performance and responsiveness of programs, enabling it to use system resources more efficiently. This is not only due to the popularity of multi-core processors and the advancement of software and hardware technology, but also to developers’ In-depth understanding and technical innovation of thread programming.
So what is a thread? A thread is an execution context, which contains a lot of state data: each thread has its own execution flow, call stack, error code, signal mask, and private data. The Linux kernel uses tasks ( Task ) to represent an execution flow.
1.1.1 Execution flow
The instructions that are executed sequentially in a task will form an instruction sequence ( the history of the IP register value ). This instruction sequence is an instruction stream, and each thread will have its own execution flow. Consider the following code ( the code block in this article is C++ ):
int calc(int a, int b, char op) {
int c = 0;
if (op == '+')
c = a + b;
else if (op == '-')
c = a - b;
else if (op == '*')
c = a * b;
else if (op == '/')
c = a / b;
else
printf("invalid operation\n");
return c;
}
The calc function is compiled into assembly instructions. One line of C code corresponds to one or more assembly instructions. If calc is executed in a thread, these machine instructions will be executed in sequence. However, the sequence of executed instructions may not be completely consistent with the order of the code. Statements such as branches and jumps in the code, as well as the compiler’s rearrangement of instructions and the processor’s out-of-order execution will affect the actual execution order of the instructions.
1.1.2 Logical threads vs hardware threads
Threads can be further divided into logical threads and hardware threads.
logical thread
Program threads are a logical concept, also called tasks, soft threads, and logical threads. The execution logic of the thread is described by code. For example, write a function to sum the elements of an integer array:
int sum(int a[], int n) {
int x = 0;
for (int i = 0; i < n; ++i)
x += a[i];
return x;
}
The logic of this function is very simple, it does not call other functions ( more complex functional logic can call other functions within the function ). We can call this function in a thread to sum an array; we can also set sum as the entry function of a thread. Each thread will have an entry function, and the thread starts executing from the entry function. The sum function describes the logic, that is, what to do and how to do it, which is partial to design; but it does not describe the material, that is, it does not describe who does the thing, and the thing ultimately needs to be dispatched to the entity for completion.
hardware thread
Corresponding to the logical thread is the hardware thread, which is the material basis for the logical thread to be executed.
In the field of chip design, a hardware thread usually refers to a hardware unit that is used to execute an instruction sequence. A CPU may have multiple cores, and the core may also support hyper-threading. The two hyper-threads in one core reuse some hardware. From a software perspective, there is no need to distinguish between the real Core and the beyond VCore. Basically, it can be considered as two independent execution units. Each execution unit is a logical CPU. From a software perspective, the CPU only needs to focus on logic. CPU. Which CPU/core a software thread is executed on, and when it is executed, is not controlled by the application programmer. It is determined by the operating system, and the scheduling system in the operating system is responsible for this work.
1.2 Relationship between threads, cores, and functions
The thread entry function is the starting point of thread execution. The thread starts from the entry function and executes instructions one after another. In the middle, it may call other functions. Then its control flow will be transferred to the called function to continue execution. There are other functions in the called function. You can continue to call other functions, thus forming a function call chain.
In the previous example of array summation, if the array is particularly large, even a simple loop accumulation may take a long time. This integer array can be divided into multiple small arrays, or expressed as a two-dimensional array ( array of arrays) , each thread is responsible for summing a small array, multiple threads execute concurrently, and finally the results are accumulated.
Therefore, in order to improve processing speed, multiple threads can be allowed to execute the same ( or similar ) calculation logic on different data sections. The same processing logic can have multiple execution instances ( threads ), which corresponds to data splitting threads. Of course, you can also specify different entry functions for the two threads to let each thread execute different calculation logic, which corresponds to logical splitting of threads.
Let’s use an example to illustrate the relationship between threads, cores and functions. Suppose there are two types of work to do: walking the dog and sweeping the floor:
- To walk a dog is to tie a leash on the dog and then lead it for a walk around the community. This sentence describes the logic of walking the dog, which corresponds to the function definition. It is a static concept that corresponds to the design.
- Every job ultimately requires people to do it, and people correspond to hardware: CPU/Core/VCore, which is the material basis for the task to be completed.
So what corresponds to software threads? Task splitting.
an example
Suppose there are 2 dogs that need to be walked and 3 rooms that need to be cleaned. Walking the dog can be split into 2 tasks, one task is to walk the puppy, and the other task is to walk the big dog; cleaning the room is split into 3 tasks, and 3 rooms correspond to 3 tasks. After executing such a split strategy, There will be 2+3=5 tasks generated. But if there are only 2 people, 2 people cannot do 5 things at the same time. Letting someone do something at a certain time is the responsibility of the scheduling system.
If John is walking his puppy, it means that one thread is being executed. If John is sweeping room A, it means that another thread is being executed. It can be seen that thread is a dynamic concept.
Software threads are not always executing for various reasons. The above example is due to insufficient manpower, so the task of walking the big dog is still waiting to be executed. Other reasons include interruption, preemption, conditional dependencies, etc. For example, if Li Si receives a call while sweeping the floor, and he needs to deal with more urgent matters ( answering the phone ), the sweeping of the floor will be suspended. If Li Si continues sweeping the floor after making the call, the thread will continue to be executed.
If there is only one person, the above five tasks can still be completed sequentially or interleavedly, so multi-threading is a programming model. Multi-threading does not necessarily require multiple CPUs and multiple Cores. A single-CPU single-Core system can still run multi-threaded programs ( although Maximizing the utilization of the processing power of multiple CPUs and multiple Cores is an important goal of multi-threaded programming ). One person cannot do multiple things at the same time, nor can a single CPU/Core. The operating system uses time slicing technology to deal with the challenge of multi-task execution that far exceeds the number of CPUs/Cores. You can also assign some tasks to only certain people to complete, which corresponds to CPU affinity and core binding.
1.3 Program, process, thread, coroutine
Processes and threads are two important concepts in the field of operating systems. They are both different and related.
1.3.1 Executable program
After the C/C++ source file is processed by the compiler ( compilation + linking ), an executable program file will be generated. Different systems have different formats, such as the ELF format of Linux systems and the EXE format of Windows systems. The executable program file is a static concept.
1.3.2 What is a process?
Each execution of an executable program on the operating system corresponds to a process. A process is a dynamic concept: a process is an executing program. Executing the same executable file multiple times will generate multiple processes, just like a class can create multiple instances. Process is the basic unit of resource allocation.
1.3.3 What is a thread?
Multiple threads within a process represent multiple execution streams, and these threads execute independently in concurrent mode. In the operating system, the smallest unit scheduled for execution is a thread rather than a process. Process is a logical concept presented to users through shared storage space. Multiple threads in the same process share address space and file descriptors. Shared address space means that the code ( function ) area, global variables, heap, and stack of the process are all used by the process. Multi-thread sharing within.
1.3.4 The relationship between processes and threads
Let’s take a look at Linus’s discussion first. In an email in 1996, Linus elaborated on his profound insights into the relationship between processes and threads. He wrote in the email:
- Distinguishing processes and threads into different entities is a traditional approach carrying historical baggage. There is no need to make such a distinction, and even this way of thinking is a major mistake.
- Processes and threads are the same thing: a context of execution ( Context Of Execution ), referred to as COE, whose state includes:
- CPU status ( registers, etc. )
- MMU status ( page map )
- Permission status ( uid, gid, etc. )
- Various communication states ( open files, signal handlers, etc. )
- Conventional wisdom holds that the main difference between processes and threads is that threads have CPU state ( and possibly other minimum necessary states ), while other context comes from the process; however, this distinction is incorrect and is a stupid self-imposed limitation. .
- The Linux kernel believes that there is no so-called concept of processes and threads at all, only COEs ( called tasks in Linux ). Different COEs can share some states with each other, and the concepts of processes and threads are built up through such sharing.
- From an implementation point of view, threads under Linux are currently implemented by LWP. Threads are lightweight processes. All threads are implemented as processes, so threads and processes are described by task_struct. This can also be seen through the /proc file system. Threads and processes have a relatively equal status. For multi-threading, the original process is called the main thread, and they form a thread group together.
- In short, the kernel should not be designed based on the concept of process/thread, but should be designed around the COE way of thinking, and then expose limited interfaces to users to meet the requirements of the pthreads library.
1.3.5 Coroutine
With multiple execution flows in user mode, the cost of context switching is lower than that of threads. After WeChat transformed the backend system with coroutines, it has achieved greater throughput and higher stability. Nowadays, the coroutine library has also entered the new C++20 standard.
1.4 Why multi-threading is needed
1.4.1 What is multithreading
The concurrent execution of multiple threads in a process is called multi-threading. Each thread is an independent execution stream. Multi-threading is a programming model that has nothing to do with the processor and is related to the design.
Reasons for requiring multithreading include:
- Parallel computing : Make full use of multiple cores to improve overall throughput and speed up execution.
- Background task processing : Separate the background thread from the main thread. It is indispensable in specific scenarios, such as responsive user interfaces, real-time systems, etc.
We use 2 examples to illustrate.
1.4.2 Improving processing capabilities through multi-thread concurrency
Suppose you want to write a program to count the number of word occurrences in a batch of text files. The input of the program is a list of file names and the output is a mapping of words to counts.
// Type alias: mapping from word to count
using word2count = std::map<std::string, unsigned int>;
// Merge a "list of word-to-count mappings"
word2count merge(const std::vector<word2count>& w2c_list) {/*todo*/}
// Count the occurrences of words in a file (word-to-count mapping)
word2count word_count_a_file(const std::string& file) {/*todo*/}
// Count the occurrences of words in a batch of text files
word2count word_count_files(const std::vector<std::string>& files) {
std::vector<word2count> w2c_list;
for (auto &file : files) {
w2c_list.push_back(word_count_a_file(file));
}
return merge(w2c_list);
}
int main(int argc, char* argv[]) {
std::vector<std::string> files;
for (int i = 1; i < argc; ++i) {
files.push_back(argv[i]);
}
auto w2c = word_count_files(files);
return 0;
}
This is a single-threaded program, and the word_count_files function is called by the main function in the main thread. If there are not many files or the files are not large, you will get the statistical results quickly after running this program. Otherwise, it may take a long time to return the results.
Re-examining this program, you will find that the function word_count_a_file accepts a file name and spits out the local results calculated from the file. It does not depend on other external data and logic and can be executed concurrently. Therefore, a separate thread can be started for each file. Run word_count_a_file, wait until all threads have finished executing, and then merge to get the final result.
In fact, it may not be appropriate to start a thread for each file, because if there are tens of thousands of small files, then start tens of thousands of threads, each thread will run for a short time, and a lot of time will be spent on thread creation and destruction. Improved design:
- Open a thread pool, the number of threads is equal to the number of Cores or twice the number of Cores ( strategy ).
- Each worker thread attempts to fetch a file from the file list ( the file list needs to be protected with a lock ).
- Successfully, count the number of word occurrences in this file.
- If it fails, the worker thread exits.
- After all worker threads exit, merge the results in the main thread.
Such a multi-threaded program can speed up processing. Similar processing can be used for the previous array sum. If the program is run on a multi-CPU multi-Core machine, it can make full use of the advantages of multi-CPU multi-Core hardware. Multi-threaded accelerated execution is multi-threaded. One of the obvious main purposes.
1.4.3 Changing the way programs are written through multi-threading
Secondly, some scenarios will have blocking calls. If multi-threading is not used, the code will be difficult to write.
For example, a program needs to monitor the standard input ( keyboard ) while performing intensive calculations. If there is input from the keyboard, the input will be read and parsed for execution. However, if the call to obtain keyboard input is blocked and no input comes from the keyboard at this time, Then other logic will not get a chance to execute.
The code will look like this:
// Receive input from the keyboard, and after interpretation, it will construct and return a Command object
Command command = getCommandFromStdInput();
// Execute the command
command.run();
In response to this situation, we usually start a separate thread to receive input, and use another thread to process other calculation logic to avoid processing input and blocking other logic processing. This is also a typical application of multi-threading, which changes the writing of programs. Method, this is the second one.
1.5 Thread related concepts
1.5.1 Time Slicing
The CPU first executes thread A for a period of time, then executes thread B for a period of time, and then executes thread A for a period of time. The CPU time is divided into short time slices and allocated to different threads for execution. The strategy is CPU time slicing. Time slicing is an extreme simplification of the scheduling strategy. In fact, the scheduling strategy of the operating system is very sophisticated and is much more complicated than simple time slicing. If one second is divided into a large number of very short time slices, such as 100 10 millisecond time slices, 10 milliseconds is too short for the human senses, so that the user cannot detect the delay, as if the computer is overwhelmed by the user’s task Exclusive ( actually not ), the operating system obtains the effect of this task exclusive CPU through the abstraction of the process ( another abstraction is that the process exclusive storage through virtual memory ).
1.5.2 Context switching
The process of migrating the task currently running on the CPU and selecting a new task to be executed on the CPU is called scheduling. The process of task scheduling will cause a context switch ( context swap ), that is, the state of the thread currently running on the CPU is saved and Restoring the state of the thread to be executed is done by the operating system and requires CPU time ( sys time ).
1.5.3 Thread-safe functions and reentrancy
A process can have multiple threads running at the same time. These threads may execute a function at the same time. If the result of concurrent execution of multiple threads is the same as the result of sequential execution of a single thread, then it is thread-safe. Otherwise, it is not thread-safe.
Shared data is not accessed. Shared data includes global variables, static local variables, and class member variables. Functions that only operate parameters and have no side effects are thread-safe functions. Thread-safe functions can be reentrant by multiple threads. Each thread has an independent stack, and function parameters are stored in registers or on the stack, and local variables are on the stack. Therefore, functions that only operate parameters and local variables are called concurrently by multiple threads without data competition.
There are many programming interfaces in the C standard library that are not thread-safe, such as time operation/conversion related interfaces: ctime()/gmtime()/localtime(). The C standard provides a thread-safe version with the _r suffix, such as:
char* ctime_r(const time* clock, char* buf);
The thread-safe versions of these interfaces generally need to pass an additional char * buf parameter. In this case, the function will operate on this buf instead of sharing data based on static, thus meeting the requirements of thread safety.
1.5.4 Thread private data
Because global variables ( including static variables in modules ) are shared by all threads in the process, sometimes application design needs to provide thread-private global variables. This variable is only valid in the thread in which the function is executed, but can span Multiple functions are accessed.
For example, in a program, each thread may need to maintain a linked list, and the same function will be used to operate the linked list. The simplest method is to use thread-related data structures with the same name but different variable addresses. Such a data structure can be maintained by the Posix thread library and become thread-specific data ( Thread-specific Data, or TSD) .Posix has interfaces related to thread private data, while languages such as C/C++ provide the thread_local keyword to provide direct support at the language level.
1.5.5 Blocking and non-blocking
A thread corresponds to an execution flow. Under normal circumstances, the instruction sequence will be executed sequentially, and the calculation logic will advance forward. But if for some reason, the execution logic of a thread cannot continue to move forward, then we say that the thread is blocked. It’s like coming home from get off work, but walking to the door and finding that you don’t have the key. You can only linger at the door and let time pass without being able to enter the room. There are many reasons for thread blocking, such as:
- The thread is suspended by the operating system because it acquires a certain lock. If the acquire sleep lock fails, the thread will give up the CPU, and the operating system will schedule another runnable thread to execute on the CPU, and the scheduled thread will be added to the waiting queue. , enter sleep state.
- The thread calls a blocking system call and waits, such as reading data from a socket with no data arriving, or reading messages from an empty message queue.
- The thread compactly executes the test & setup instructions in the loop without success. Although the thread is still executing on the CPU, it is just busy waiting ( equivalent to wasting the CPU ). Subsequent instructions cannot be executed, and the logic cannot be advanced.
If a system call or programming interface may cause thread blocking, it is called a blocking system call; the corresponding is a non-blocking call. Calling a non-blocking function will not cause blocking. If the requested resource cannot be satisfied, It will return immediately and report the reason through the return value or error code. The calling place can choose to retry or return.
2 Multi-thread synchronization
I have talked about the basic knowledge related to multi-threading before. Now let’s move on to the second topic, multi-thread synchronization.
2.1 What is multi-thread synchronization?
Multiple threads in the same process will share data, and concurrent access to shared data will cause Race Condition. The official translation of this word is race condition, but the translation of condition into condition is confusing, especially for beginners, it is not enough It is clear and concise. The translation software shows that condition has the meaning of status and status, and it may be translated into competition status to be more straightforward.
Multi-thread synchronization refers to:
- Coordinate multiple threads’ access to shared data to avoid data inconsistencies.
- Coordinate the sequence of events so that multiple threads converge at a certain point and advance as expected. For example, a thread needs to wait for another thread to complete a certain task before it can proceed with the next step of the thread.
To master multi-thread synchronization, you need to first understand why multi-thread synchronization is needed and what situations require synchronization.
2.2 Why synchronization is needed
Understanding why synchronization ( Why ) is the key to multi-threaded programming, it is even more important than mastering the multi-thread synchronization mechanism ( How ) itself. Identifying where synchronization is required is the difficulty in writing multi-threaded programs. Only by accurately identifying the data that needs to be protected and the points that need to be synchronized, and then cooperating with the appropriate synchronization mechanism provided by the system or language, can safe and efficient multi-threaded programs be written.
Here are a few examples to explain why synchronization is needed.
Example 1
There is a character array msg with a length of 256 used to save messages. The functions read_msg() and write_msg() are used to read and write msg respectively:
// example 1
char msg[256] = "this is old msg";
char* read_msg() {
return msg;
}
void write_msg(char new_msg[], size_t len) {
memcpy(msg, new_msg, std::min(len, sizeof(msg)));
}
void thread1() {
char new_msg[256] = "this is new msg, it's too looooooong";
write_msg(new_msg, sizeof(new_msg));
}
void thread2() {
printf("msg=%s\n", read_msg());
}
If thread 1 calls write_msg() and thread 2 calls read_msg(), the operations are concurrent and unprotected. Because the length of msg is 256 bytes, completing a write of up to 256 bytes requires multiple memory cycles. While thread 1 is writing a new message, thread 2 may read inconsistent data. That is, it is possible to read “this is new msg”, and the second half of the content “it’s very…” Thread 1 has not had time to write it, and it is not a complete new message.
In this example, the inconsistency manifests itself as incomplete data.
Example 2
For example, for a binary search tree ( BST ) node, a structure has 3 components:
- a pointer to the parent node
- a pointer to the left subtree
- a pointer to the right subtree
// example 2
struct Node {
struct Node *parent;
struct Node *left_child, *right_child;
};
These three components are related. To add a node to the BST, these three pointer fields must be set. To delete the node from the BST, the pointer fields of the node’s parent, left child node, and right child node must be modified. Modifications to multiple pointer fields cannot be completed in one instruction cycle. If the writing of one component is completed and other components have not been modified, it may be read by other threads, but at this time some pointer fields of the node have not yet been modified. After setting it up, it may be wrong to retrieve the number through the pointer field.
Example 3
Consider two threads incrementing the same integer variable. The initial value of the variable is 0. We expect that the value of the variable will be 2 after the two threads complete the increment.
// example 3
int x = 0;
void thread1() { ++x; }
void thread2() { ++x; }
A simple auto-increment operation includes three steps:
- Load: Read the value of variable x from memory and store it in the register
- Update: Complete auto-increment in register
- Save: Write the new value of x located in the register to memory
Two threads execute ++x concurrently, let’s see what the real situation looks like:
- If two threads execute self-increment one after another, they will be staggered in time. Whether it is 1 first and then 2, or 2 first and then 1, then the final value of x is 2, as expected. But multi-thread concurrency does not ensure that access to a variable is completely staggered in time.
- If the time is not completely staggered, assuming that thread 1 is executed on core 1 and thread 2 is executed on core 2, then a possible execution process is as follows:
- First, thread 1 reads x into the register of core 1, and thread 2 also loads the value of x into the register of core 2. At this time, the copies of x stored in the registers of both cores are all 0.
- Then, thread 1 completes the increment and updates the copy of the value of x in the register ( 0 to 1 ), and thread 2 also completes the increment and updates the copy of the value of x in the register ( 0 to 1 ).
- Then, thread 1 writes the updated new value 1 to the memory location of variable x.
- Finally, Thread 2 writes the updated new value 1 to the same memory location, and the final value of variable x is 1, which is not as expected.
The same problem may occur if thread 1 and thread 2 are interleaved on the same core. This problem has nothing to do with the hardware structure. The reason why unexpected situations occur is mainly because the three steps of “loading + updating + saving” cannot be completed in one memory cycle. Multiple threads read and write the same variable concurrently. Without synchronization, data inconsistency will occur.
In this example, the inconsistency is manifested in the fact that the final value of x could be either 1 or 2.
Example 4
Implement a queue using a C++ class template:
// example 4
template <typename T>
class Queue {
static const unsigned int CAPACITY = 100;
T elements[CAPACITY];
int num = 0, head = 0, tail = -1;
public:
// Enqueue
bool push(const T& element) {
if (num == CAPACITY) return false;
tail = (++tail) % CAPACITY;
elements[tail] = element;
++num;
return true;
}
// Dequeue
void pop() {
assert(!empty());
head = (++head) % CAPACITY;
--num;
}
// Check if empty
bool empty() const {
return num == 0;
}
// Access the front element
const T& front() const {
assert(!empty());
return elements[head];
}
};
Code explanation:
- T elements[] saves data; 2 cursors are used to record the positions ( subscripts) of the head and the tail of the team respectively. The push() interface first moves the tail cursor and then adds the element to the end of the queue.
- The pop() interface moves the head cursor and pops up the head element of the queue ( logically pops up ).
- front() interface, returns a reference to the front element of the queue.
- front() and pop() make assertions first, and the client code that calls pop()/front() needs to ensure that the queue is not empty.
Assume that there is a Queue<int> instance q. Because calling pop directly may assert fails, we encapsulate a try_pop() with the following code:
Queue<int> q;
void try_pop() {
if (!q.empty()) {
q.pop();
}
}
If multiple threads call try_pop(), there will be problems. Why?
Reason : The two operations of empty judgment and dequeue cannot be completed in one instruction cycle. If thread 1 intersperses in after judging that the queue is not empty, the empty judgment is also false, so it is possible that two threads compete to pop up the only element.
In a multi-threaded environment, reading variables and then performing further operations based on the value will cause errors if such logic is not protected. This is a problem introduced by the way data is used.
Example 5
Let’s look at a simple, simple multi-threaded read and write to int32_t.
// example 5
int32_t data[8] = {1,2,3,4,5,6,7,8};
struct Foo {
int32_t get() const { return x; }
void set(int32_t x) { this->x = x; }
int32_t x;
} foo;
void thread_write1() {
for (;;) { for (auto v : data) { foo.set(v); } }
}
void thread_write2() {
for (;;) { for (auto v : data) { foo.set(v); } }
}
void thread_read() {
for (;;) { printf("%d", foo.get()); }
}
There are 2 writing threads and 1 reading thread. The writing thread sets the x component of the foo object using the element value in data in an infinite loop, and the reading thread simply prints the x value of the foo object. If the program keeps running, will the data printed out at the end contain data other than the data initialization value?
Is there something wrong with the implementation of Foo::get? If there is a problem? What’s the problem?
Example 6
Look at a program that uses an array to implement a FIFO queue. One thread writes put() and another thread reads get().
// example 6
#include <iostream>
#include <algorithm>
// Circular queue implemented with an array
class FIFO {
static const unsigned int CAPACITY = 1024; // Capacity: needs to be a power of 2
unsigned char buffer[CAPACITY]; // Buffer for storing data
unsigned int in = 0; // Write position
unsigned int out = 0; // Read position
unsigned int free_space() const { return CAPACITY - (in - out); }
public:
// Returns the actual length of data written (<= len), returns less than len when there is insufficient free space
unsigned int put(unsigned char* src, unsigned int len) {
// Calculate the actual writable data length (<=len)
len = std::min(len, free_space());
// Calculate how much free space from the in position to the end of the buffer
unsigned int l = std::min(len, CAPACITY - (in & (CAPACITY - 1)));
// 1. Place data into the buffer starting at in, up to the end of the buffer
memcpy(buffer + (in & (CAPACITY - 1)), src, l);
// 2. Place remaining data at the beginning of the buffer (if not finished in the previous step), len - l being 0 means the previous step completed the data write
memcpy(buffer, src + l, len - l);
in += len; // Update in position, incrementing it; it will wrap around after reaching uint32_max
return len;
}
// Returns the actual length of data read (<= len), returns less than len when there is not enough data in the buffer
unsigned int get(unsigned char *dst, unsigned int len) {
// Calculate the actual readable data length
len = std::min(len, in - out);
unsigned int l = std::min(len, CAPACITY - (out & (CAPACITY - 1)));
// 1. Copy data from out position to dst, up to the end of the buffer
memcpy(dst, buffer + (out & (CAPACITY - 1)), l);
// 2. Continue copying data from the beginning of the buffer (if not finished in the previous step), len - l being 0 means the previous step completed the data retrieval
memcpy(dst + l, buffer, len - l);
out += len; // Update out position, incrementing it; it will wrap around after reaching uint32_max
return len;
}
};
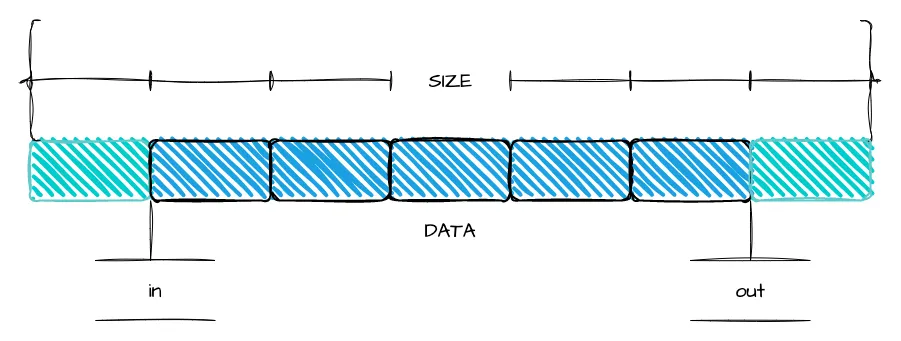
The ring queue is only a logical concept. Because an array is used as the data structure, the actual physical storage is not a ring type.
- put() is used to put data into the queue. The parameters src+len describe the data information to be put.
- get() is used to get data from the queue. The parameters dst+len describe where the data is to be read and how many bytes to read.
- If the capacity is carefully selected to the nth power of 2, three benefits can be obtained:
- Very skillful use of unsigned integer overflow wrapping to facilitate handling of in and out movements.
- It is convenient to calculate the length by using the bitwise AND operation & without having to divide the remainder.
- Search kfifo for a more detailed explanation.
- in and out are 2 cursors:
- in is used to point to the storage location of newly written data. When writing, you only need to simply increase in.
- out is used to indicate the location in the buffer from which to read data. When reading, simply increase out.
- The reason why in and out can increase monotonically in operation is due to the clever choice of capacity mentioned above.
- For simplicity, the queue capacity is limited to 1024 bytes and expansion is not supported. This does not affect the discussion of multi-threading.
When writing, the data is written first and then the in cursor is moved; when reading, the data is copied first and then the out cursor is moved; only after the in cursor is moved, the consumer gets the opportunity to get the newly inserted data.
Intuition tells us that there will be problems if two threads read and write concurrently without synchronization, but is there really a problem? If so, what exactly is the problem? How to solve it?
2.3 What to protect
In multi-threaded programs, what we want to protect is data rather than code. Although there are critical codes and sync methods in languages such as Java, what ultimately needs to be protected is the data accessed by the code.
2.4 Serialization
If a thread is accessing a shared ( critical ) resource, other threads cannot execute code that accesses the same resource before it ends the access ( code that accesses critical resources is called critical code ). If other threads want to access the same resource, they You must wait until that thread’s access is completed before it can get the opportunity to access. There are many such examples in reality. For example, when cars pass a checkpoint on a highway, assuming there is only one lane at the checkpoint, no matter how many lanes there are on the highway, they can only pass through the checkpoint one car after another, filing in from a single lane. Imposing such constraints on multi-threaded access to shared resources is called serialization.
2.5 Atomic operations and atomic variables
Regarding the problem of the previous two threads incrementing the same integer variable, if the three steps of “load, update, store” are an inseparable whole, that is, the increment operation ++x satisfies atomicity, the above program will not There will be problems.
Because in this case, if two threads execute ++x concurrently, there will only be two results:
- Thread a ++x, then thread b ++x, the result is 2.
- Thread b ++x, then thread a ++x, the result is 2.
In addition, the third situation will not occur. Which thread a or b comes first depends on thread scheduling, but it does not affect the final result.
Both the Linux operating system and the C/C++ programming language provide integer atomic variables. Operations such as self-increment and self-decrement of atomic variables are atomic. The operation is atomic, which means that it is an undivided operation as a whole. When users of atomic variables observe it, they can only see the unfinished and completed states, but not the semi-completed state.How to ensure atomicity is an implementation-level issue. Application programmers only need to understand atomicity logically and be able to use it appropriately. Atomic variables are very suitable for application scenarios such as counting and generating serial numbers.
2.6 Lock
Many examples have been given previously to explain the problems caused by concurrent access to data by multiple threads without synchronization. Next, we will explain how to use locks to achieve synchronization.
2.6.1 Mutex lock
Regarding the problem of thread 1 write_msg() + thread 2 read_msg(), if thread 1 cannot read_msg() while thread 1 is writing_msg(), then there will be no problem. This requirement is actually to allow multiple threads to have mutually exclusive access to shared resources.
Mutex lock is a synchronization mechanism that can meet the above requirements. Mutex means exclusive. It can ensure that only one thread can access that shared resource at the same time. Mutex locks have and only have 2 states:
- locked status
- Unlocked state
Mutex provides two interfaces for locking and unlocking:
- Locking (acquire) : When the mutex is in the unlocked state, the lock is successfully acquired ( the lock is set to the locked state ) and returned; when the mutex is in the locked state, then try to lock it The locked thread will be blocked until the mutex is unlocked.
- Unlock (release) : Release the lock by setting the lock to the unlocked state. Other threads that are stuck in waiting due to applying for locks will get the opportunity to execute. If there are multiple waiting threads, only one will obtain the lock and continue execution.
We configure a mutex lock for a shared resource and use the mutex lock for thread synchronization. Then all threads need to follow the three steps of “locking, accessing, and unlocking” to access the resource:
DataType shared_resource;
Mutex shared_resource_mutex;
void shared_resource_visitor1() {
// step1: lock
shared_resource_mutex.lock();
// step2: operate shared_resouce
// operation1
// step3: unlock
shared_resource_mutex.unlock();
}
void shared_resource_visitor2() {
// step1: lock
shared_resource_mutex.lock();
// step2: operate shared_resouce
// operation2
// step3: unlock
shared_resource_mutex.unlock();
}
shared_resource_visitor1() and shared_resource_visitor2() represent different operations on shared resources. Multiple threads may call the same operation function or may call different operation functions.Assume that thread 1 executes shared_resource_visitor1(). This function applies for a lock before accessing the data. If the mutex has been locked by other threads, the thread calling this function will be blocked in the locking operation until other threads have accessed the data. , release ( unlock ) the lock, and thread 1 blocked in the locking operation will be awakened and try to lock:
- If no other thread applies for the lock, then thread 1 successfully locks and obtains access to the resource. After completing the operation, the lock is released.
- If other threads are also applying for the lock, then:
- If other threads grab the lock, thread 1 continues to block.
- If thread 1 grabs the lock, then thread 1 will access the resource and then release the lock, allowing other threads competing for the lock to have the opportunity to continue execution.
If you cannot bear the cost of blocking due to lock failure, you can call the try_lock() interface of the mutex, which will return immediately after the lock fails.
Note : Applying for a lock before accessing a resource and then releasing the lock after accessing it is a programming contract. Data consistency is guaranteed by complying with the contract. It is not a hard restriction, that is, if other threads follow the three steps, and another Threads do not follow this convention, the code may compile and the program may run, but the results may be wrong.
2.6.2 Read-write lock
Read-write locks are similar to mutex locks. When applying for a lock, if the lock cannot be satisfied, it will block. However, read-write locks are also different from mutex locks. Read-write locks have three states:
- Read lock status added
- Write lock status added
- Unlocked state
Corresponding to 3 states, the read-write lock has 3 interfaces: add read lock, add write lock, and unlock:
- Add read lock : If the read-write lock is in the write-locked state, the thread applying for the lock is blocked; otherwise, the lock is set to the read-locked state and returns successfully.
- Add write lock : If the read-write lock is in the unlocked state, set the lock to the write-locked state and return successfully; otherwise, block.
- Unlock : Set the lock to the unlocked state and return.
Read-write locks improve thread parallelism and can improve throughput. It allows multiple reading threads to read shared resources at the same time. When the writing thread accesses the shared resources, other threads cannot execute. Therefore, the read-write lock is suitable for occasions where “reading is greater than writing” when accessing shared resources. Read-write locks are also called “shared mutex locks”. Multiple read threads can access the same resource concurrently, which corresponds to the concept of sharing, while write threads are mutually exclusive. When a write thread accesses a resource, other threads, regardless of whether they are reading or writing, can The critical code area cannot be entered.
Consider a scenario: If there are threads 1, 2, and 3 sharing resource x, the read-write lock rwlock protects the resource, thread 1 reads and accesses a resource, and then thread 2 accesses the same resource , so thread 2 is blocked, and then after a while, thread 3 Also read and access resource , then it will still gain access, but thread 2 that writes the resource will always be blocked.
In order to prevent the shared read thread from starving the write thread, usually the implementation of the read-write lock will give priority to the writing thread. Of course, this depends on the implementation of the read-write lock. As a user of the read-write lock, you must understand its semantics and usage scenarios. That’s enough.
2.6.3 Spin lock
The interface of spinlock is similar to that of mutex, but the implementation principle is different. When the thread fails to acquire the spin lock, it will not actively give up the CPU and enter the sleep state. Instead, it will be busy waiting. It will compactly execute the test and set ( Test-And-Set ) instructions until TAS succeeds, otherwise It just keeps occupying the CPU to do TAS.
Spin locks have some expectations for usage scenarios. It expects that the lock will be released soon after the acquire spin lock is successful. The time for the thread to run the critical section code is very short, and the logic of accessing shared resources is simple. In this case, other acquire spin locks The thread only needs to wait for a short time to obtain the spin lock, thereby avoiding being scheduled to fall into sleep. It assumes that the cost of spin is lower than that of scheduling, and it does not want to spend time on thread scheduling ( thread scheduling needs to be saved and restoring the context requires CPU ).
Kernel state threads can easily meet these conditions, because the interrupt processing function running in the kernel state can turn off scheduling to avoid CPU preemption, and some processing functions called by kernel state threads cannot sleep and can only use spin locks.
For applications running in user mode, it is recommended to use sleep locks such as mutex locks. Because the application is running in user mode, although it is easy to keep the critical section code short, the lock holding time may still be very long. On a time-sharing multi-tasking system, when the time quota of the user-mode thread is exhausted, or on a system that supports preemption, a higher-priority task is ready, then the thread holding the spin lock will be blocked by the system. Scheduling, the process of holding the lock may be very long, and other threads busy waiting for the spin lock will consume CPU resources in vain. In this case, it is contrary to the concept of the spin lock.
The optimized mutex implementation of the Linux system will first perform a limited number of spins when locking. Only after the limited number of spins fail, it will go to sleep and give up the CPU. Therefore, in actual use, its performance is good enough. . In addition, the spin lock must be in a multi-CPU or multi-Core architecture. Imagine if there is only one core, then when it executes the spin logic, other threads cannot run, and there is no chance to release the lock.
2.6.4 Lock granularity
Set the lock granularity reasonably. Too large a granularity will reduce performance, and too small a granularity will increase the complexity of code writing.
2.6.5 Lock scope
The scope of the lock should be as small as possible to minimize the time the lock is held.
2.6.6 Deadlock
There are two typical reasons why a program deadlocks:
ABBA lock
Suppose there are two resources X and Y in the program, which are protected by locks A and B respectively. After thread 1 holds lock A, it wants to access resource Y. Before accessing resource Y, it needs to apply for lock B. If thread 2 is holding Lock B and want to access resource X. In order to access resource X, thread 2 needs to apply for lock A. Thread 1 and Thread 2 hold locks A and B respectively, and both hope to apply for the lock held by the other party. Because the thread’s application for the lock held by the other party is not satisfied, it will fall into waiting and will have no chance to release its own lock. If there is a lock, the other party’s execution flow will be unable to move forward, resulting in a stalemate, infinite mutual waiting, and then deadlock.
The above situation seems obvious, but if the amount of code is large, sometimes the logic of this deadlock will not be so simple. It is covered up by the complex calling logic, but if you peel it off, the most fundamental logic is what is described above. That way. This situation is called ABBA lock, that is, a thread holds lock A and applies for lock B, while another thread holds lock B and applies for lock A. This situation can be achieved through try lock, trying to acquire the lock, and if unsuccessful, release the lock you hold without going anywhere. Another solution is lock sorting. The locking operations of the two locks A/B follow the same order ( for example, A first and then B ), which can also avoid deadlock.
self deadlock
For locks that do not support repeated locking, if a thread holds a lock and then applies for the lock again, because the lock is already held by itself, applying for the lock again will not be satisfied, leading to a deadlock.
2.7 Condition variables
Condition variables are often used in the producer-consumer model and need to be used in conjunction with mutexes.Suppose you want to write a network processing program. The I/O thread receives the byte stream from the socket, deserializes it to generate messages ( custom protocol ), and then delivers them to a message queue. A group of worker threads are responsible for processing the messages from Messages are fetched from the queue and processed. This is a typical producer-consumer model. The I/O thread produces messages ( puts to the queue ), the Work thread consumes messages ( gets from the queue ), and the I/O threads and Work threads access the message queue concurrently. Obviously, the message queue is Competing for resources requires synchronization.
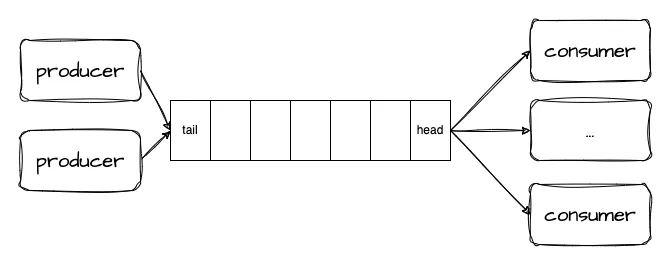
You can configure a mutex lock for the queue. It is locked before put and get operations, and then unlocked after the operation is completed. The code is almost like this:
void io_thread() {
while (1) {
Msg* msg = read_msg_from_socket();
msg_queue_mutex.lock();
msg_queue.put(msg);
msg_queue_mutex.unlock();
}
}
void work_thread() {
while (1) {
msg_queue_mutex.lock();
Msg* msg = msg_queue.get();
msg_queue_mutex.unlock();
if (msg != nullptr) {
process(msg);
}
}
}
Each thread in the work thread group is busy checking whether there is a message in the message queue. If there is a message, it will take it out and then process the message. If there is no message, it will keep checking in the loop. In this way, even if the load is very light, the work_thread is still Will consume a lot of CPU time.
Of course we can add a short sleep between two queries to free up the CPU, but what is the appropriate setting for this sleep time? If the setting is too long, the incoming messages will not be processed in time ( the delay increases ); if the setting is too short, CPU resources will be consumed innocently. This method of continuous inquiry is called polling in programming.
Logically, the polling behavior is equivalent to you waiting for a package to be delivered to the small post office downstairs. After you go downstairs to check whether it is there, you go upstairs to your room, and then go downstairs to check again. You keep going up and downstairs to check. In fact, you can It doesn’t have to be like this. Why not wait until the package arrives and ask the doorman to call you to pick it up?
Condition variables provide a mechanism similar to notify, which allows two types of threads to meet at one point. Condition variables allow threads to wait for a certain condition to occur. The condition itself is protected by a mutex lock, so the condition variable must be used with a mutex lock. The lock protects the condition. The thread first obtains the lock before changing the condition, then changes the condition state, and then unlocks it. Finally, a notification is issued. Before being awakened, the sleeping thread waiting for the condition must first obtain the lock and then determine the condition status. If the condition is not established, it will continue to sleep and release the lock.
Corresponding to the above example, the condition for the worker thread to wait is that the message queue has messages ( not empty ). Use condition variables to rewrite the above code:
void io_thread() {
while (1) {
Msg* msg = read_msg_from_socket();
{
std::lock_guard<std::mutex> lock(msg_queue_mutex);
msg_queue.push_back(msg);
}
msg_queue_not_empty.notify_all();
}
}
void work_thread() {
while (1) {
Msg* msg = nullptr;
{
std::unique_lock<std::mutex> lock(msg_queue_mutex);
msg_queue_not_empty.wait(lock, []{ return !msg_queue.empty(); });
msg = msg_queue.get();
}
process(msg);
}
}
std::lock_guard is a RAII wrapper class for mutexes. In addition to automatically unlocking in the destructor, std::unique_lock also supports active unlock().
When the producer delivers a message to msg_queue, it needs to lock msg_queue. The code to notify the work thread can be placed after unlocking. The waiting condition for msg_queue_not_empty must be protected by msg_queue_mutex. The second parameter of wait is a lambda expression, because there will be Multiple work threads are awakened. After the thread is awakened, it will reacquire the lock, check the condition, and sleep again if it does not hold. The use of condition variables needs to be very careful, otherwise it is easy to fail to wake up.The programming interfaces of C language condition variables and Posix condition variables are similar to those of C++ and are conceptually consistent, so they will not be introduced here.
2.8 Lock-free and lock-free data structures
2.8.1 The problem of lock synchronization
Thread synchronization is divided into blocking synchronization and non-blocking synchronization.
- The mechanisms provided by the system such as mutexes, signals, and condition variables are blocking synchronization, which will cause the calling thread to block when competing for resources.
- Non-blocking synchronization refers to achieving synchronization without blocking through certain algorithms and technical means in the absence of locks.
The lock is a blocking synchronization mechanism. The disadvantage of the blocking synchronization mechanism is that it may hang your program. If the thread holding the lock crashes or hangs, the lock will never be released, and other threads will fall into infinite waiting; in addition, it It may also lead to issues such as priority inversion. Therefore, we need non-blocking synchronization mechanisms such as lock-free.
2.8.2 What is lock-free
Lock-free does not have lock synchronization problems. All threads can execute atomic instructions without hindrance instead of waiting. For example, a thread reads an atomic type variable, and a thread writes an atomic variable. They do not wait for anything. Hardware atomic instructions ensure that there will be no data inconsistency, writing data will not be half-complete, and reading data will not be half-read.
So what exactly is lock-free? Some people say that lock-free means lock-less programming that does not use mutex/semaphores and the like. This sentence is strictly speaking not true. Let’s first take a look at the wiki’s description of Lock-free:
Lock-freedom allows individual threads to starve but guarantees system-wide throughput. An algorithm is lock-free if, when the program threads are run for a sufficiently long time, at least one of the threads makes progress (for some sensible definition of progress). All wait-free algorithms are lock-free. In particular, if one thread is suspended, then a lock-free algorithm guarantees that the remaining threads can still make progress. Hence, if two threads can contend for the same mutex lock or spinlock, then the algorithm is not lock-free. (If we suspend one thread that holds the lock, then the second thread will block.)
Translate it:
- Paragraph 1 : Lock-free allows single thread starvation but guarantees system-level throughput. If a program thread executes for a long enough time, then at least one thread will advance forward, then the algorithm is lock-free.
- Paragraph 2 : In particular, if a thread is suspended, the lock-free algorithm ensures that other threads can still move forward.
The first paragraph defines lock-free, and the second paragraph explains lock-free: if two threads compete for the same mutex lock or spin lock, then it is not lock-free; because if it is suspended ( Hang ) the thread holding the lock, then the other thread will be blocked.
This description in the wiki is very abstract and not intuitive enough. Let me explain it a little further: lock-free describes the properties of code logic. Most codes that do not use locks have this property. People often confuse the two concepts of lock-free and lock-free. In fact, lock-free is a description of the nature of the code ( algorithm ), which is an attribute; while lock-free refers to how the code is implemented, which is a means.
The key description of lock-free is: if a thread is suspended, other threads should be able to continue, and it requires system-wide throughput.
As shown in the figure, two threads are on the timeline, and at least one thread is in the running state.

Let’s look at the opposite example. Suppose we want to use locks to implement a lock-free queue. We can directly use thread-unsafe std::queue + std::mutex to do it:
template <typename T>
class Queue {
public:
void push(const T& t) {
q_mutex.lock();
q.push(t);
q_mutex.unlock();
}
private:
std::queue<T> q;
std::mutex q_mutex;
};
If threads A/B/C execute the push method at the same time, thread A, which enters first, obtains the mutex lock. Threads B and C are stuck waiting because they cannot obtain the mutex lock. At this time, if thread A is permanently suspended due to some reason ( such as an exception, or waiting for a certain resource ), then thread B/C that also performs push will be permanently suspended, and the entire system ( system-wide ) will not be permanently suspended. It cannot be pushed forward, and this obviously does not meet the requirements of lock-free. Therefore: all concurrency implementations based on locks ( including spinlock ) are not lock-free.Because they will all encounter the same problem: that is, if the execution of the thread/process currently holding the lock is permanently suspended, the execution of other threads/processes will be blocked. Compared with the description of lock-free, it allows part of the process ( understood as execution flow ) to starve to death but must ensure the continued progress of the overall logic. Lock-based concurrency obviously violates the lock-free requirements.
2.8.3 CAS loop implements Lock-free
Lock-Free synchronization mainly relies on the read-modify-write primitive provided by the CPU. The famous “Compare And Swap” CAS ( Compare And Swap ) is an atomic operation implemented through the cmpxchg series of instructions on the X86 machine. CAS logic is expressed in code It goes like this:
bool CAS(T* ptr, T expect_value, T new_value) {
if (*ptr != expect_value) {
return false;
}
*ptr = new_value;
return true;
}
CAS accepts 3 parameters:
- memory address
- Expected value, usually the old value in the memory address pointed to by the first parameter is passed
- new value
Logic description: CAS compares the value in the memory address with the expected value. If it is not the same, it returns failure. If it is the same, it writes the new value into the memory and returns success.
Of course, this C function only describes the logic of CAS. The operation of this function is not atomic, because it can be divided into several steps: reading memory values, judging, and writing new values. Other operations can be inserted between each step. But as mentioned before, atomic instructions are equivalent to packaging these steps. It may be implemented through the lock; cmpxchg instruction, but that is an implementation detail, and programmers should pay more attention to logically understanding its behavior.
The code to implement Lock-free through CAS usually uses loops. The code is as follows:
do {
T expect_value = *ptr;
} while (!CAS(ptr, expect_value, new_value));
- Create a local copy of shared data: expect_value.
- Modify the local copy as needed, load it from the shared data pointed to by ptr and assign it to expect_value.
- Check whether the shared data is equal to the local copy, and if so, copy the new value to the shared data.
The third step is the key. Although CAS is atomic, the two steps of loading expect_value and CAS are not atomic. Therefore, we need to use a loop. If the value of the ptr memory location has not changed ( *ptr == expect_value ), then store the new value and return success; otherwise, it means that after loading expect_value, the memory location pointed to by ptr has been modified by other threads. This When it returns failure, reload expect_value and try again until success.
CAS loop supports multi-threaded concurrent writing. This feature is very useful. Because of multi-thread synchronization, we often face the problem of multiple writing. We can implement the Fetch-and-add ( FAA ) algorithm based on CAS, which looks like this:
T faa(T& t) {
T temp = t;
while (!compare_and_swap(x, temp, temp + 1));
}
The first step is to load the value of the shared data into temp, and the second step is to compare and store the new value until success.
2.8.4 Lock-free data structure: lock-free stack
Lock-free data structures protect shared data through non-blocking algorithms rather than locks. The non-blocking algorithm ensures that threads competing for shared resources will not have their execution suspended indefinitely due to mutual exclusion; the non-blocking algorithm is lock-free because Regardless of scheduling, system-level progress is ensured. The wiki definition is as follows:
A non-blocking algorithm ensures that threads competing for a shared resource do not have their execution indefinitely postponed by mutual exclusion. A non-blocking algorithm is lock-free if there is guaranteed system-wide progress regardless of scheduling.
The following is a lock-free stack implemented by C++ atomic compare_exchange_weak() ( from CppReference ):
template <typename T>
struct node {
T data;
node* next;
node(const T& data) : data(data), next(nullptr) {}
};
template <typename T>
class stack {
std::atomic<node<T>*> head;
public:
void push(const T& data) {
node<T>* new_node = new node<T>(data);
new_node->next = head.load(std::memory_order_relaxed);
while (!head.compare_exchange_weak(new_node->next, new_node,
std::memory_order_release,
std::memory_order_relaxed));
}
};
Code analysis:
- Node ( node ) saves data of type T and holds a pointer to the next node.
- The std::atomic<node *> type indicates that the pointer of Node is placed in atomic, not the Node itself, because the pointer is 8 bytes on a 64-bit system, which is equal to the machine word length. No matter how long it is, atomicity cannot be guaranteed.
- The stack class contains the head member, which is a pointer to the head node. The head node pointer is equivalent to the top pointer of the heap. There is no node at the beginning, and head is NULL.
- In the push function, a new node is first created based on the data value, and then it is placed on the top of the heap.
- Because the stack is implemented using a linked list, if the new node is to become the new top of the heap ( equivalent to inserting the new node as the new head node ), then the next field of the new node must point to the original head node, and let head Point to the new node.
- new_node->next = head.load points the next field of the new node to the original head node, and then head.compare_exchange_weak(new_node->next, new_node) makes head point to the new node.
- C++ atomic’s compare_exchange_weak() is slightly different from the above-mentioned CAS. When head.load() is not equal to new_node->next, it will reload the value of head.load() to new_node->next.
- Therefore, between loading the head value and CAS, if other threads call the push operation and change the value of head, it does not matter. The thread’s CAS fails this time and can just try again next time.
- When multiple threads push at the same time, if any thread blocks/hangs at any step, other threads will continue to execute and eventually return, which is nothing more than executing the while loop several times.
Such behavioral logic obviously conforms to the definition of lock-free. Note that using CAS+Loop to implement spin lock does not conform to the definition of lock-free. Pay attention to the distinction.
2.9 Program: Program Order
For a single-threaded program, the code is executed sequentially, line by line, just like the order in which we write the program. for example:
a = 1;
b = 2;
A=1 will be executed first and then b=2. The lines of code seen from the program perspective will execute the calling program in sequence. We build the software on this basis and use this as the basis for discussion.
2.10 Memory Order: Memory Order
The memory order corresponding to the program program refers to the order in which memory reading and writing actually occur when observed from a certain angle. The memory operation sequence is not unique. In a CPU containing core0 and core1, core0 and core1 have their own memory operation sequences, and the two memory operation sequences are not necessarily the same. The order of global memory operations seen from the perspective of a CPU containing multiple Cores is also different from the order of memory operations seen from the perspective of a single core. This difference is unacceptable for some program logic, for example:
The program requires that a = 1 be executed before b = 2, but the memory operation sequence may not be the same. Assigning 1 to a is not guaranteed to occur before assigning 2 to b. This is because:
- If the compiler thinks that the assignment to b does not depend on the assignment to a, then it is entirely possible to adjust the compiled assembly instruction sequence at compile time.
- Even if the compiler does not make adjustments, during execution, the assignment to b may be executed before the assignment to a.
Although for a Core, as mentioned above, the memory operation sequence observed by this Core does not necessarily conform to the program sequence, the memory operation sequence and the program sequence must produce the same result, no matter which value is assigned to a or b on a single Core. Occurs first, the result is that a is assigned to 1 and b is assigned to 2. If out-of-order execution on a single core will affect the result, then the compiler’s instruction rearrangement and CPU out-of-order execution will not occur, and the hardware will provide This guarantee.However, in multi-core systems, the hardware does not provide such a guarantee. In multi-threaded programs, the different memory operation sequences observed by the Core working in each thread, and the difference between these sequences and the global memory sequence, often lead to multi-thread synchronization failure. Therefore, A synchronization mechanism is needed to ensure that the memory order is consistent with the program order. The introduction of the memory barrier ( Memory Barrier ) is to solve this problem. It allows different Cores to reach agreement with each other, as well as the Core and the global memory order.
2.11 Out-of-order Execution
Out-of-order execution will cause the memory order to be different from the program order. There are many reasons for out-of-order execution, such as compiler instruction rearrangement, superscalar instruction pipeline, predictive execution, Cache-Miss, etc. The order of memory operations cannot exactly match the order of the program, which may cause confusion. Since there are side effects, why do we need to execute it out of order? The answer is for performance.Let’s first take a look at how early in-order processors ( In-order Processors ) processed instructions before out-of-order execution?
- Instruction acquisition, loading instructions from the code section memory area to I-Cache
- decoding
- If the instruction operand is available ( for example, the operand is in a register ), the instruction is dispatched to the corresponding function module; if the operand is not available, usually it needs to be loaded from memory, the processor will stall until they are ready and until the data is Load into Cache or copy into register
- Instructions are executed by functional units
- The functional unit writes the result back to a register or memory location
How do Out-of-order Processors process instructions?
- Instruction acquisition, loading instructions from the code section memory area to I-Cache
- decoding
- Distribute instructions to the instruction queue
- The instruction waits in the instruction queue. Once the operand is ready, the instruction leaves the instruction queue, even if the instruction before it has not been executed ( out of order )
- Instructions are dispatched to functional units and executed
- The execution results are put into the queue ( Store Buffer ) instead of written directly into the Cache
- Only after the instruction results requested earlier are written into the cache, the instruction execution results are written into the cache. By sorting the instruction results and writing them into the cache, the execution looks orderly.
Out-of-order execution of instructions is the result, but the cause is not just the out-of-order execution of the CPU, but caused by two factors:
- Compilation time : Instruction rearrangement ( compiler ). The compiler will rearrange instructions for performance. Two lines in the source code may change the order of instructions after being compiled by the compiler, but the compiler will make instructions based on a set of rules. Rearrangement, instructions with obvious dependencies will not be rearranged arbitrarily, and the rearrangement of instructions cannot destroy the program logic.
- Runtime : Out-of-order execution ( CPU ), CPU’s superscalar pipeline, predictive execution, Cache-Miss, etc. may cause instructions to be executed out of order, that is, subsequent instructions may be executed before previous instructions.
2.12 Store Buffer
Why do you need Store Buffer?
Consider the following code:
void set_a() {
a = 1;
}
- Assume that set_a() running on core0 assigns a value of 1 to the integer variable a. The computer usually does not write directly to the memory, but modifies the corresponding Cache Line in the Cache.
- If there is no a in the Cache of Core0, the assignment operation ( store ) will cause Cache Miss
- Core0 will stall waiting for the Cache to be ready ( load variable a from the memory to the corresponding Cache Line ), but stalling will damage the CPU performance, which is equivalent to the CPU stalling here, wasting precious CPU time.
- With Store Buffer, when the variable is not in place in the Cache, the Store operation will be buffered first. Once the Store operation enters the Store Buffer, the core will consider that its Store is completed. When the Cache is then in place, the store will automatically write Corresponds to Cache.
Therefore, we need Store Buffer. Each Core has an independent Store Buffer. Each Core accesses a private Store Buffer. Store Buffer helps the CPU cover the delay caused by Store operations.
What problems will Store Buffer cause?
a = 1;
b = 2;
assert(a == 1);
In the above code, when asserting a==1, you need to read ( load ) the value of variable a. If a is in the Cache before being assigned, the old value of a ( maybe between 1 and 1) will be read from the Cache. value other than the value ), so the assertion may fail. But such a result is obviously unacceptable, and it violates the most intuitive program sequence.
The problem is that in addition to being stored in memory, variable a also has two copies: one in the Store Buffer and one in the Cache. If the relationship between these two copies is not considered, data inconsistency will occur. So how to fix this problem?You can first check whether there is a pending new value of a in the Store Buffer when loading data in the Core. If so, take the new value; otherwise, take a copy of a from the cache. This technology is often used in multi-stage pipeline CPU design, and is called Store Forwarding. With Store Buffer Forwarding, we can ensure that the execution of single-core programs follows program sequence, but there are still problems with multi-cores. Let us examine the following program:
Multi-core memory ordering problem
int a = 0; // Cached by CPU1
int b = 0; // Cached by CPU0
// Executed by CPU0
void x() {
a = 1;
b = 2;
}
// Executed by CPU1
void y() {
while (b == 0);
assert(a == 1);
}
Assume that both a and b are initialized to 0; CPU0 executes the x() function, and CPU1 executes the y() function; variable a is in the local Cache of CPU1, and variable b is in the local Cache of CPU0.
- When CPU0 executes a = 1, because a is not in CPU0’s local cache, CPU0 will write the new value 1 of a into the Store Buffer and send a Read Invalidate message to other CPUs.
- CPU1 executes while (b == 0), because b is not in CPU1’s local cache, CPU1 will send a Read message to other CPUs to obtain the value of b.
- CPU0 executes b = 2. Because b is in the local Cache of CPU0, it directly updates the copy of b in the local cache.
- CPU0 receives the read message from CPU1 and sends the new value 2 of b to CPU1; at the same time, the status of the Cache Line storing b is set to Shared to reflect the fact that b is cached by both CPU0 and CPU1.
- After receiving the new value 2 of b, CPU1 ends the loop and continues to execute assert(a == 1). Because the value of a in the local Cache is 0 at this time, the assertion fails.
- After CPU1 receives the Read Invalidate from CPU0, it updates the value of a to 1, but it is too late. The program has collapsed in the previous step ( assert failed ).
what to do? The answer is left to the section on memory barriers.
2.13 Invalidate Queue
Why do you need Invalidate Queue?
When a variable is loaded into the cache of multiple cores, the Cache Line is in the Shared state. If Core1 wants to modify this variable, it needs to notify other Cores by sending the inter-core message Invalidate to set the corresponding Cache Line to Invalid. When other Cores After both Invalid this CacheLine, the Core obtains exclusive rights to the variable and can modify it at this time.
The core that receives the Invalidate message needs to respond to the Invalidate ACK. Each core responds like this. Only after all cores have responded can Core1 modify it, which wastes the CPU.
In fact, after receiving the Invalidate message, other cores will cache the Invalidate message to the Invalidate Queue and immediately reply with ACK. The actual Invalidate action can be delayed. This is because the Core can quickly return the Invalidate request issued by other Cores. , which will not cause unnecessary Stall of the Core for Invalidate requests. On the other hand, it also provides further optimization possibilities. For example, the Invalidate of multiple variables in a CacheLine can be saved and done at once.But the way to write the Store Buffer is actually Write Invalidate. It is not written to the memory immediately. If other cores read from the memory at this time, it may be inconsistent.
2.14 Memory barrier
Is there any way to ensure that the assignment to a must precede the assignment to b? Yes, memory barriers are used to provide this guarantee.
Memory Barrier, also known as memory barrier, barrier instruction, etc., is a type of synchronization barrier instruction. It is a synchronization point for the CPU or compiler in the operation of random access to memory. All read and write operations before the synchronization point are Only after execution can you begin to perform operations after this point. Semantically, all write operations before the memory barrier must be written to the memory; read operations after the memory barrier can obtain the results of the write operations before the synchronization barrier.
The memory barrier actually provides a mechanism to ensure that multiple lines written sequentially in the code will be stored in the memory in the order they are written. It mainly solves the problem of writing memory gaps caused by the introduction of Store Buffer.
void x() {
a = 1;
wmb();
b = 2;
}
Inserting a memory barrier statement between a=1 and b=2 as above will ensure that a=1 takes effect before b=2, thereby solving the problem of out-of-order memory access. Then the inserted smp_mb(), What will it do?
Recall the previous process, after CPU0 executes a = 1, it executes the smp_mb() operation. At this time, it will mark all data items in the Store Buffer ( marked ), and then continue to execute b = 2, but at this time Although b is in its own cache, because there is a marked entry in the store buffer, CPU0 does not modify b in the cache, but writes it to the Store. Buffer; so after CPU0 receives the Read message, it will send the 0 value of b to CPU1, so it continues to spin in while (b).
In short, when Core executes the write memory barrier ( wmb ), if the Store Buffer still has pending store operations, they will be marked. Subsequent Store operations cannot be executed until the marked Store operations enter the memory. , so wmb guarantees the order of operations before and after the barrier. It does not care whether the memory order of multiple operations before the barrier and the memory order of multiple operations after the barrier are consistent with the Global Memory Order.
a = 1;
b = 2;
wmb();
c = 3;
d = 4;
wmb() guarantees that “a=1;b=2” occurs before “c=3;d = 4”. It does not guarantee the memory order of a = 1 and b = 2, nor does it guarantee the memory order of c = 3 and d = 4. Internal sequence.
Problems introduced by Invalidate Queue
Just like the introduction of Store Buffer will affect the memory consistency of Store, the introduction of Invalidate Queue will affect the memory consistency of Load. Because the Invalidate queue will cache messages sent by other cores, for example, the message of Invalidate certain data is processed by delay, causing the core to hit the data in the Cache Line, and this Cache Line should have been marked invalid by the Invalidate message. How to solve this problem?
- One idea is that the hardware ensures that the Invalidate Queue is cleared every time data is loaded, so as to ensure the strong order of the load operation.
- The idea of the software is to imitate the definition of wmb() and add rmb() constraints. rmb() marks our invalidate queue. When a load operation occurs, all invalidate commands marked by the previous rmb() must be executed before the subsequent load can occur. In this way, we ensure that the order observed by load is equal to the global memory order before and after rmb().
So, we can modify the code like this:
a = 1;
wmb();
b = 2;
while(b != 2) {};
rmb();
assert(a == 1);
System support for memory barriers
When the gcc compiler encounters the embedded assembly statement asm volatile(“” ::: “memory”), it will use it as a memory barrier to reorder memory operations, that is, the various compilation optimizations before this statement will not continue until after this statement.
The Linux kernel provides the function barrier() to allow the compiler to ensure that previous memory accesses are completed before subsequent ones.
#define barrier() __asm__ __volatile__("" ::: "memory")
CPU memory barrier:
- General barrier to ensure orderly read and write operations, mb() and smp_mb().
- Write operation barrier only ensures that write operations are ordered, wmb() and smp_wmb().
- The read operation barrier only ensures that the read operations are in order, rmb() and smp_rmb().
summary
- In order to improve the performance of the processor, store buffer ( and the corresponding implementation of store buffer forwarding ) and invalidate queue were introduced in SMP.
- The introduction of store buffer means that the store order on the core may not match the order of global memory. For this, we need to use wmb() to solve this problem.
- The existence of the invalidate queue causes the load order observed on the core to be inconsistent with the global memory order. For this, we need to use rmb() to solve this problem.
- Since wmb() and rmb() only act on the store buffer and invalidate queue respectively, these two memory barriers jointly ensure the order of store/load.
3 Pseudo sharing
The phenomenon of multiple threads reading and writing variables in the same Cache Line at the same time, causing the CPU Cache to frequently fail, thus degrading program performance, is called False Sharing .
const size_t shm_size = 16*1024*1024; //16M
static char shm[shm_size];
std::atomic<size_t> shm_offset{0};
void f() {
for (;;) {
auto off = shm_offset.fetch_add(sizeof(long));
if (off >= shm_size) break;
*(long*)(shm + off) = off;
}
}
Examine the above program: shm is a 16M byte memory. The L3 Cache of the machine I tested is 32M. 16M bytes can ensure that shm can fit in the cache. In the loop of the f() function, shm is regarded as an array of long type, and each element is assigned a value in turn. shm_offset is used to record the offset position. shm_offset.fetch_add(sizeof(long)) atomically increases the value of shm_offset ( because x86_64 The length of long on the system is 8, so shm_offset increases by 8 each time ), and return the value before the increase. After assigning a value to each element of the long array on shm, end the loop and return from the function.
Because shm_offset is an atomic type variable, calling f() from multiple threads can still work normally. Although multiple threads will compete for shm_offset, each thread will exclusively assign values to each long element. Multi-thread parallelization will speed up the assignment operation of shm. . We add multi-threaded calling code:
std::atomic<size_t> step{0};
const int THREAD_NUM = 2;
void work_thread() {
const int LOOP_N = 10;
for (int n = 1; n <= LOOP_N; ++n) {
f();
++step;
while (step.load() < n * THREAD_NUM) {}
shm_offset = 0;
}
}
int main() {
std::thread threads[THREAD_NUM];
for (int i = 0; i < THREAD_NUM; ++i) {
threads[i] = std::move(std::thread(work_thread));
}
for (int i = 0; i < THREAD_NUM; ++i) {
threads[i].join();
}
return 0;
}
- Start two worker threads work_thread in the main function.
- The working thread assigns values to shm for a total of 10 rounds. Each subsequent round will access the shm data in the Cache. Step is used for synchronization between work_threads in each round.
- After the working thread calls f(), it will increase step. After both working threads have called it, the value of step increases to n * THREAD_NUM, while() will end the loop, reset shm_offset, and start a new round of shm matching. assignment.
As shown in the picture:
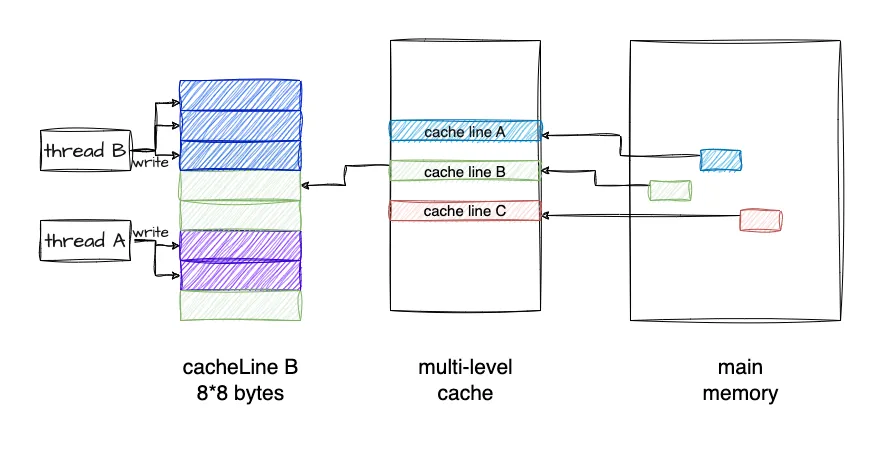
After compiling and executing the above program, the following results are produced:
time ./a.out
real 0m3.406s
user 0m6.740s
sys 0m0.040s
The time command is used for time measurement. After the a.out program is completed, the time taken will be printed. The real column shows that it took 3.4 seconds.
3.1 Improved version of f_fast
Let’s slightly modify the f function. The improved version of the f function is named f_fast:
void f_fast() {
for (;;) {
const long inner_loop = 16;
auto off = shm_offset.fetch_add(sizeof(long) * inner_loop);
for (long j = 0; j < inner_loop; ++j) {
if (off >= shm_size) return;
*(long*)(shm + off) = j;
off += sizeof(long);
}
}
}
In the for loop, shm_offset no longer increases by 8 bytes each time ( sizeof(long) ), but 8*16=128 bytes. Then in the inner loop, 16 long continuous elements are assigned in sequence, and then the next A round of loop adds 128 bytes again until the assignment to shm is completed. As shown in the picture:
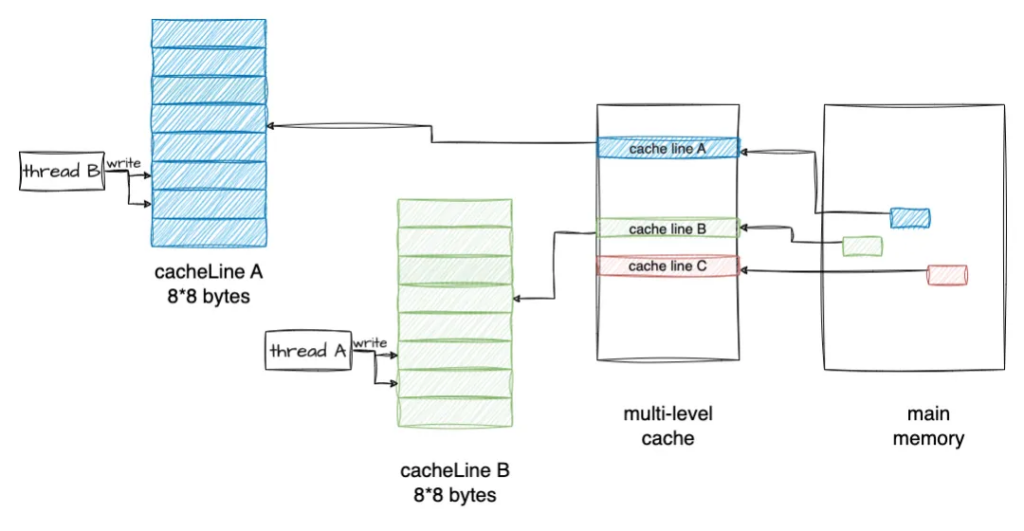
After compiling and re-executing the program, the result shows that the time consumption is reduced to 0.06 seconds. Compared with the previous method, which took 3.4 seconds, the performance of f_fast is significantly improved.
time ./a.out
real 0m0.062s
user 0m0.110s
sys 0m0.012s
Differences in behavior between f and f_fastThe shm array has a total of 2M long elements, because 16M / sizeof(long) gives 2M:
1. f() function behavior logic
- The shm elements will be assigned values in the work_thread of thread 1 and thread 2 in an interleaved manner. The 2M long elements of shm will be assigned to the two threads one after another in sequence.
- Possible behavior: Element 1 is assigned by thread 1, element 2 is assigned by thread 2, then element 3 and element 4 are assigned by thread 1, then element 5 is assigned by thread 2…
- Every time an element is dispatched, shm_offset will be atomically increased by 8 bytes, so there will be no situation where two threads assign values to the same element.
2. f_fast() function behavior logic
- Each time an element is dispatched, shm_offset is atomically increased by 128 bytes ( 16 elements ).
- These 16 bytes are assigned to thread 1 or thread 2 as a whole; although thread 1 and thread 2 will still operate shm elements interleavedly, with 16 elements ( 128 bytes ) as a unit, these 16 consecutive elements Will not be distributed to different threads.
- The 16 elements dispatched at once will be assigned one after another in a thread ( in the inner loop ).
3.2 Why f_fast is faster
At first glance, it seems that the call frequency of shm_offset.fetch_add() in f_fast() has been reduced to 1/16 of the original. There is reason to suspect that the reduced competition for atomic variables leads to faster program execution. For verification, let’s add an atomic variable test’s fetch_add to the inner loop. The competition for the test atomic variable will be as fierce as shm_offset.fetch_add() in the f() function. The modified f_fast code becomes as follows:
void f_fast() {
for (;;) {
const long inner_loop = 16;
auto off = shm_offset.fetch_add(sizeof(long) * inner_loop);
for (long j = 0; j < inner_loop; ++j) {
test.fetch_add(1);
if (off >= shm_size) return;
*(long*)(shm + off) = j;
off += sizeof(long);
}
}
}
In order to prevent the call to test.fetch_add(1) from being optimized by the compiler, we print out the value of test at the end of the main function. After compiling and testing, the results show that the execution time only slightly increased to real 0m0.326s. Obviously, it is not the reduction in the frequency of atomic calls that causes the performance to soar.Re-examine the logic in the f() loop: The operations in the f() loop are very simple: atomic addition, judgment, and assignment. We commented out the assignment in f() and tested it again, and found that its speed has been greatly improved. It seems that the line of code *(long*)(shm + off) = off executes slowly, but this is obviously just One line assignment. Let’s disassemble it and see that it is just a mov instruction. The source operand is a register and the destination operand is a memory address. The data is copied from the register to a memory address. Why is it so slow?
3.3 Reasons
Now the answer is revealed: the culprit causing the poor performance of f() is false sharing ( false sharing ). So what is pseudo-sharing? To clarify this issue, we have to contact the CPU architecture and how the CPU accesses data, and review the multi-core Cache structure.
Background knowledge
Modern CPUs can have multiple cores. Each core has its own L1-L2 cache. L1 distinguishes between data cache ( L1-DCache ) and instruction cache ( L1-ICache ). L2 does not distinguish between data and instruction cache, while L3 is a cross-cache. Core-sharing, L3 is connected to the memory through the memory bus, and the memory is shared by all CPUs and all Cores.
The speed of CPU access to L1 Cache is about 100 times that of accessing memory. Cache acts as a cache between the CPU and memory to reduce the frequency of memory access.
When loading data from memory to Cache, the length unit is Cache Line. The length of Cache Line is usually 64 bytes. Therefore, even if only one byte is read, the entire Cache Line containing that byte will be loaded. To the cache, similarly, if one byte is modified, it will eventually cause the entire Cache Line to be flushed into memory.
If a piece of memory data is accessed by multiple threads, assuming multiple threads execute in parallel on multiple Cores, then it will be loaded into the Local Cache of multiple Cores; whichever Core these threads run on will be loaded. Which Core’s Local Cache? Therefore, a piece of data in memory will have multiple copies in the Cache of different Cores at the same time.
Then, there will be a cache consistency problem. When one Core modifies a value in its cache, other Cores can no longer use the old value. This memory location will be invalidated in all caches. Additionally, because the cache operates at the granularity of cache lines rather than individual bytes, entire cache lines will be invalidated across caches. If we modify some data in the Core1 cache, the status of the Cache Line where the data is located needs to be synchronized to the caches of other Cores. The status can be synchronized between Cores through inter-core messages, such as sending Invalidate messages to other cores and receiving The core that receives this message will invalidate the corresponding Cache Line, and then reload the latest data from the memory.
Of course, the same Cache Line loaded into multiple Core caches will be marked as Shared state. To modify the cache line in the shared state, you need to obtain the modification right ( exclusive ) of the cache line first. The MESI protocol is used To ensure the consistency of multi-core cache, please refer to the MESI article for more details.
Example analysis
Assume that thread 1 runs on Core1 and thread 2 runs on Core2.
- Because shm is accessed concurrently by two threads, thread 1 and thread 2, the memory data of shm will be loaded into the Cache of two Cores at the same time with Cache Line granularity. Because it is shared by multiple cores, the Cache Line is marked as Shared state. .
- Assume that thread 1 writes an 8-byte data ( sizeof(long) ) at offset 64. To modify a Cache Line whose status is Shared, Core1 will send an inter-core communication message to Core2 to get the Cache Line’s exclusivity, after which Core1 can modify the Local Cache.
- After thread 1 executes shm_offset.fetch_add(sizeof(long)), shm_offset will increase to 72.
- At this time, thread 2 running on Core2 will also execute shm_offset.fetch_add(sizeof(long)), which returns 72 and increases shm_offset to 80.
- Thread 2 next needs to modify the memory location of shm[72], because shm[64] and shm[72] are in the same Cache Line, and this Cache Line is set to Invalidate, so it needs to reload this one from the memory. Cache Line, before that, thread 1 on Core1 needs to flush the Cache Line into memory so that thread 2 can load the latest data.
This alternate execution mode is equivalent to the need to frequently send inter-core messages between Core1 and Core2. The Cache Line of the Core that receives the message is invalidated and the data is reloaded from the memory to the Cache. This is required after each modification. Flushing the data in the Cache into the memory is equivalent to discarding the Cache, because every read and write directly deals with the memory, and the role of the Cache no longer exists, which is the reason for the low performance.This kind of multi-core and multi-thread program concurrently reads and writes the data of the same Cache Line ( memory data at adjacent locations ), resulting in frequent cache line failures and frequent memory Load/Store, which leads to a sharp decline in performance. This phenomenon is called pseudo-sharing. Pseudo sharing is a performance killer.
3.4 Another example of pseudo-sharing
Assume that threads x and y modify the a and b variables of Data respectively. If they are called frequently, poor performance will also occur. How to avoid this?
struct Data {
int a;
int b;
} data; // global
void thread1() {
data.a = 1;
}
void thread2() {
data.b = 2;
}
space for time
The idea to avoid performance degradation caused by pseudo-sharing of cache is to trade space for time. By adding padding, the two variables a and b are distributed to different Cache Lines. In this way, the modification of a and b will affect different Cache Lines. Avoid cache failure problems.
struct Data {
int a;
int padding[60];
int b;
};
There is a __cacheline_aligned_in_smp macro definition in the Linux kernel to solve the false sharing problem.
#ifdef CONFIG_SMP
#define __cacheline_aligned_in_smp __cacheline_aligned
#else
#define __cacheline_aligned_in_smp
#endif
struct Data {
int a;
int b __cacheline_aligned_in_smp;
};
From the above macro definition, we can see:
- In multi-core systems, the macro definition is __cacheline_aligned, which is the size of the Cache Line.
- On a single-core system, this macro definition is empty.
4 Summary
Several synchronization primitives provided by the pthread interface are as follows:
| Synchronization Primitive | Background | Common Application Scenarios | Advantages | Disadvantages | Notes |
|---|---|---|---|---|---|
| Mutex | Only one thread can proceed at a time | Most scenarios | Simple to use, very high performance when lock contention is low | Lower performance when contention is high | First choice; pthread has multiple locking characteristics, recommended to use standard mutex types only |
| Read-Write Lock | Allows higher concurrency; only one thread can hold the write lock, but multiple threads can hold the read lock | Suitable for scenarios where reads far outnumber writes | Better performance when there are many reads and few writes | May lead to writer starvation or reader starvation (depends on implementation) | Can be implemented as: read priority, write priority, fair. |
| Condition Variable | Allows threads to wait for specific conditions to occur without busy waiting; has notification mechanism | Producer-Consumer model | Can be used to notify threads when conditions are met | Waking up threads, re-acquiring locks, and re-checking conditions may incur additional overhead | Requires mutexes, needs to check spurious wakeups and wake multiple threads (POSIX standard allows waking up more than one thread) |
| Spin Lock | Threads do not want to spend time being rescheduled. Instead of sleeping, they busy-wait to approximate blocking, used to implement other types of locks | Lock held for short periods, used by some system functions and libraries | Non-preemptive kernel avoids interrupts, spinning time may be longer than expected (under time slice) | Not recommended for user-level use because mutexes are efficient enough | |
| Barrier | Coordinates multiple threads working in parallel; each thread waits until all threads reach a certain point before proceeding | Suitable for fixed number of threads in parallel algorithms, data initialization, etc. | Simplifies synchronization code | In some implementations, threads waiting at the barrier consume CPU resources (busy waiting) | Only applicable for a fixed number of threads; similar to Java’s CyclicBarrier or C++20’s std::barrier |
Since threads and processes under Linux are essentially LWP, the IPC ( pipeline, FIFO, message queue, semaphore ) used for inter-process communication can also be used between threads and can achieve the same effect. But since IPC resources are not cleaned up when the process exits ( because it is a system resource ), it is not recommended.
The following are some common practices that are non-locking but can also achieve thread safety or partial thread safety:
| Name | Description | Common Application Scenarios | Advantages | Disadvantages | Notes |
|---|---|---|---|---|---|
| Atomic Assignment | Simple type aligned reads and writes are usually atomic. For example, int32, int64 | Pointer assignment during double buffer switching; simple type modifications in shared memory | Lock-free and simple implementation | Essentially single processor instructions are atomic, but not all processor architectures guarantee atomicity | |
| Simple Atomic Variable (atomic) | Atomic CPU instructions implemented through compilers and languages | Native type increment/decrement and immediate value assignments, emphasizing final correctness over order | High performance, simple implementation | Implemented in gcc, C, C++, Java; no copy support for all atomic types; no floating-point atomic variables | |
| CAS (Simple Atomic Variable is a Weak CAS) | Memory barrier | Strict requirements for execution order | High performance, simple implementation | In severe contention, spinning can be very wasteful of CPU resources | |
| Double Buffer | Saves two copies in memory | Infrequently updated data | High performance, no locking required | Wastes space | Only suitable for write-once-read-many scenarios |
| Deferred Deletion Double Buffering | Maintains double buffering for a short period after update, then deletes old version; switches to new data using atomic pointer assignment | Infrequently updated data | High performance, no locking required | Limited update frequency | Only suitable for write-once-read-many scenarios |
| thread_local | Each thread holds a separate copy of data, completely avoiding thread synchronization | Threads do not need real-time interaction | High performance, no locking required | Each thread has a separate instance | |
| per-cpu Variable | Each processor has a copy of the variable | No read/write after binding to a core | High performance, no locking required | Reference: DEFINE_PER_CPU, get_cpu_var, etc. | |
| RCU (Read-Copy-Update) | Creates a copy when modification is needed, then switches to the copy | Read-mostly scenarios | See: rcu_read_lock, https://liburcu.org/ |
As you can see, many of the above methods use copies to avoid sharing data in the middle of threads. The fastest synchronization of all is the kind that never takes place , Share nothing is best.